How I am building my archive

One of my projects is to build an archive of my published writing. I'm creating this archive on Obsidian and maintaining it for personal use. I'm also putting it online, which may run afoul of copyright laws, since much of the newspaper work was done under "work for hire" rules in which the writer does not own any rights to the published work. But I'll be trying to get permission to do this.
Back when I first started at the weekly American Journal, I kept a clippings folder. Each week, I'd clip my articles and put them in a folder in chronological order. That's not necessarily a time-consuming task in a weekly newspaper, but when I started writing for my first daily newspaper, the dearly-departed Journal Tribune, I began to fall behind. So instead of clipping my articles, I just kept a copy of each print newspaper in a banker's box. This approach continued on at the Portland Press Herald, and by the time I got to the Kennebec Journal and Central Maine Morning Sentinel, I'd just sort of given up all together.
So a few years ago, when we were moving from a country house in Bowdoinham to a smaller house in Brunswick, I started to clip articles from the mass of newspapers I had collected over the years. My mother, who was retired, volunteered to take over the project and today I'd say we've got perhaps two-thirds of the newspapers processed. But to be honest, I knew that collection was woefully incomplete, and the clippings remain in boxes after yet another move.

The idea was that I would then scan each clip, OCR the contents, and save the text and the image together in a file for posterity. I chose a digital archive because I didn't want to saddle my children, or their children, with the impossible choice of eventually disposing of it. I chose Obsidian because all the files would be kept as plain text files — about as portable and future-proof as a file format can be (in the back of my head I thought I might also create some physical compendia so that there would be some physical evidence of the work that I had done). The portability aspect — the ability to use the same text file in more than one application — was critical to this project.
...the prospect of having to create a scanning station that would enable me to process a week's worth of clips at a time (if I ever wanted to complete the project) was simply too daunting.
Which brings us to today. Those clips that my mother and I dutifully cut from newspapers remain in the box: the prospect of having to create a scanning station that would enable me to process a week's worth of clips at a time (if I ever wanted to complete the project) was simply too daunting.
But I've recently stumbled on a process that promises to jump-start my plans, and it all came about practically by accident. I catalogue it here in case it inspires others.
Overview
Discovery phase: I subscribe to one of my old newspapers, the Portland Press Herald. Over the years, the current owner of the newspaper has acquired almost every other Maine daily and weekly for which I've written. About a week ago, I clicked on the "archives" link and found that the PPH had partnered with Ancestry.com's newspaper archive, Newspapers.com, and I suddenly realized I now had access to as much as 90% of my published news journalism. Not surprisingly, you can purchase a subscription directly from Newspapers.com.
Collection phase: Newspapers.com provides a tremendous search tool to find one's work. The content is stored as an image file and there are tools that enable the user to crop stories from the full-page image and save them online as "clips." Fortuitously, you can also download the clips as PDFs or image files. Being able to do this means I didn't have to scan my physical clips manually.
Text creation phase: My physical scanner had OCR software that I planned to use on my clips to create the text files, and all I had from Newspapers.com were jpeg and PDF files— so far. I started searching for software that could text the image files and apply OCR to extract the text, and I stumbled upon this site. This suggested to me that there was already an OCR output file available at Newspapers.com (of course there was, I realized later, because that is why the search works so well), and all I had to do was find it. Which I was able to do (see the recipe below)...
Editing phase: The only problem with the text created by the OCR is that it was unedited. There was no punctuation, and occasional omitted words, strange capitalized letters and misspellings. At first I manually edited the text, which really slowed me down. But in a eureka moment only possible since March 21, 2023 — the date Google opened up Bard to a general beta — I realized I could ask an large language model-based AI chatbot to edit it for me. And I was very pleased with result, an example of which is shown below.
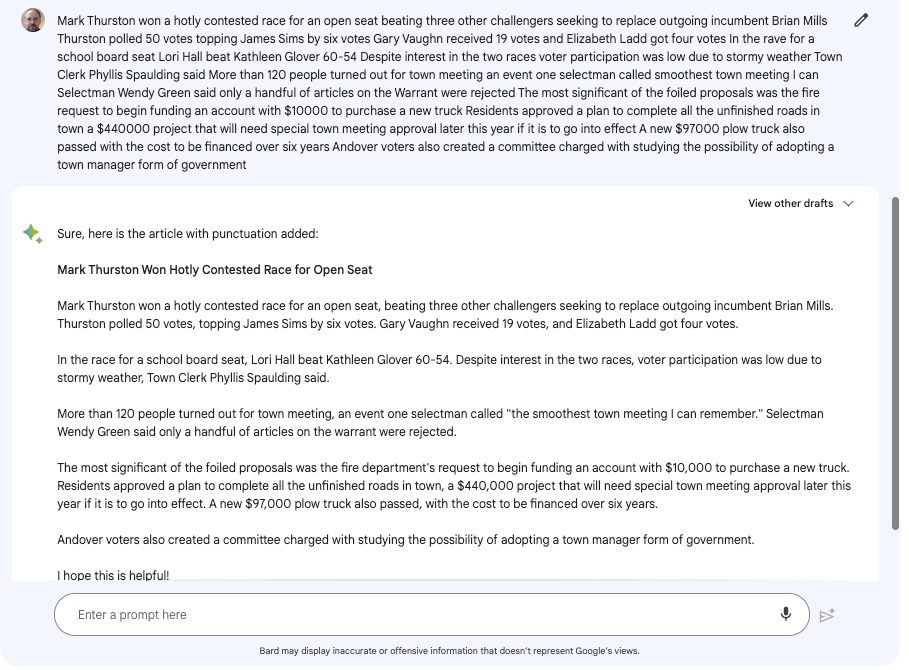
Archive filing phase: The last thing I copy from Newspapers.com is a standard citation. Then I take these materials — the image file, the edited text and the citation — and put them into an Obsidian file (sometimes called a note). In Obsidian, I keep the following structured data in YAML frontmatter:
title: "Fire truck loses, plow truck wins"
date: 1999-03-07
outlet: Portland Press Herald
keyword: brief
words: 263
status: published
version: RWT4.0
citation: Portland Press Herald. (March 7, 1999). Fire Truck loses, plow truck wins. Newspapers.com. Retrieved July 4, 2023, from https://pressherald.newspapers.com/article/portland-press-herald-fire-truck-loses/127593502/
(If you don't know what YAML means, don't worry because it's not essential to the process. I use YAML because I can use it with other Obsidian plugins to organize the clips. But even if you don't use YAML frontmatter, you should probably keep this information in your note in an organized way.)
Republication phase: Now that I have a text file with all the information I want, it's time to upload it to my site (the one you may be reading this on). I use Ulysses as a "post-Obisidan" tool to do final revisions and prepare manuscripts for publication. Ulysses was my choice for two reasons — I can point it at my Obsidian folders and it can open, edit and save the Markdown files I've created in Obsidian, and because it has the ability to publish content to my Ghost.io website with the push of a button. In this process, I publish the Markdown file to Ulysses as a draft. I then do some light editing (for instance, moving the YAML frontmatter to a toggle element in Ghost and adding a feature image from Unsplash) and publish the post. You can see an example here.
Recipe

- Navigate to Newspapers.com and sign up for an account. The service currently offers a free week so that you can try before you buy.
- Search for your byline in the keyword search box. It looks like the screenshot just above.
- Select an item from the list of results. Clicking on it will open an image of the page that your search term (in this case, byline) appears on.
- Select the clip tool in the upper right hand corner and then crop the article you'd like to clip. In the dialogue box to the right, give your clip a title and optional tag, then hit save.
- At this point, I download a copy as a jpeg. There, it's on my hard drive!
- Still on the Newspapers.com website, I then click on the view clip button. If you scroll down the resulting page, you can find the OCR text at the bottom, below the image of the clip. Copy it and paste it into your text file so that you have it. While you are at it, click on the "Source Citation" link, copy the citation, and paste it into the text file as well.
- Copy the unedited OCR text and paste it into your favorite AI chatbot. Tell it to add punctuation. Copy the output to your clipboard.
- To create the Markdown file, make a new note in Obsidian. You might want to create a template to structure your "clip" notes. Paste the contents of your clipboard into your text file. If you are using Obsidian, drag the jpeg image into the file as well. Finally, add any structured data you want into your YAML frontmatter. The basic archive file is complete.
- If you want to publish the file, you'll need to get it into your website. You can cut and paste the contents of clip note into most content management systems, since it is just text. As I said above, I use an Obsidian -> Ulysses -> Ghost workflow for revision and publication, so there's no cut and paste needed.